Linear regression é um método estatístico para encontrar relacionamentos entre variáveis.
Neste exemplo usaremos alguns conceitos básicos, como feature selection utilizando correlação, colinearidade e variação para prever o valor de uma casa.
Utilizaremos também o conceito de ordinary least squares estimation (OLS). Porém ele é executado de forma automática quando chamamos fit() em uma instância LinearRegression do Sklearn
Vamos lá:
Preparando os dados

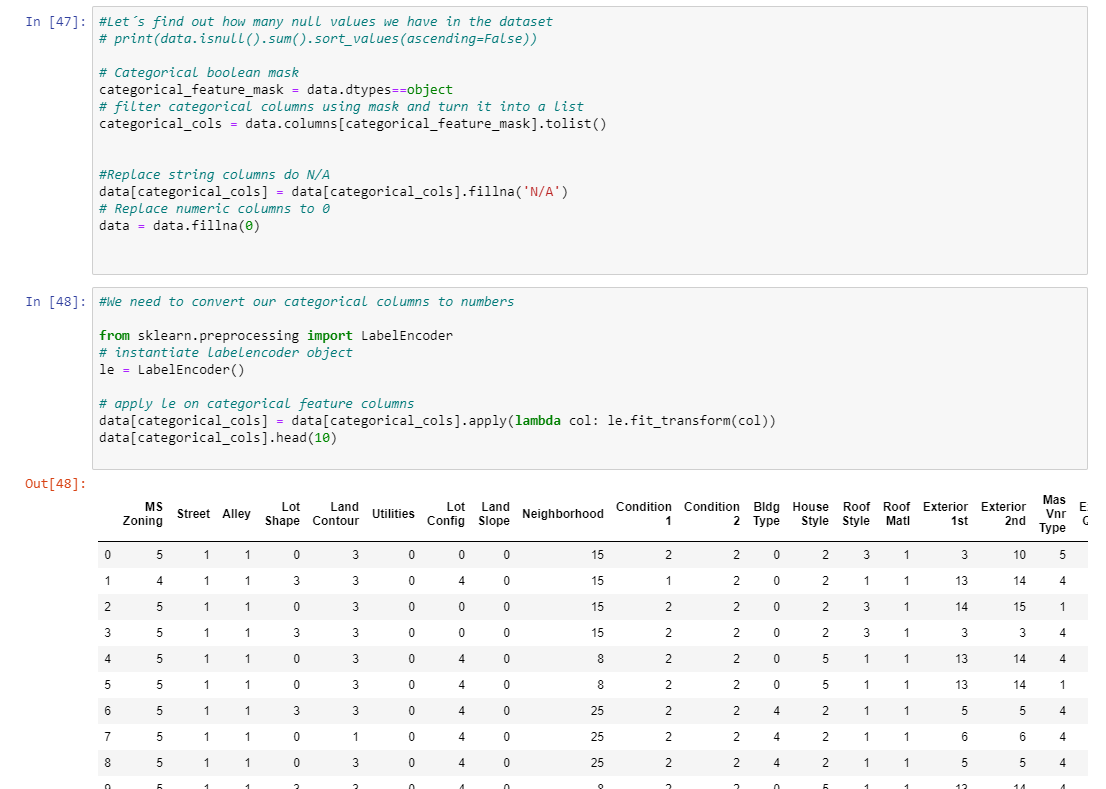
Verificando a quantidade de valores nulos.

Em seguida setando valores nulos para 0 ou N/A em caso colunas texto (categorical feature)

Em seguida convertemos as colunas com categorias para números. Mas atenção: esta nem sempre é uma boa opção, pois pode influenciar o resultado de forma negativa. Estou trabalhando desta maneira pois preciso saber qual a correlação das colunas de categorias (texto) em relação a minha coluna target SalePrice
Aqui começamos a aplicar algumas técnicas de Feature Selection
Correlação
Verificamos a correlação que as colunas possuem entre si. Oque nos importa é saber o valor do imóvel, logo temos a coluna/feature SalePrice como nosso target e precisamos saber quais colunas que possuem maior correlação com ela
Então optamos por usar apenas colunas com correlação á SalePrice maior que 0.3, reduzindo para 16 features nosso dataset

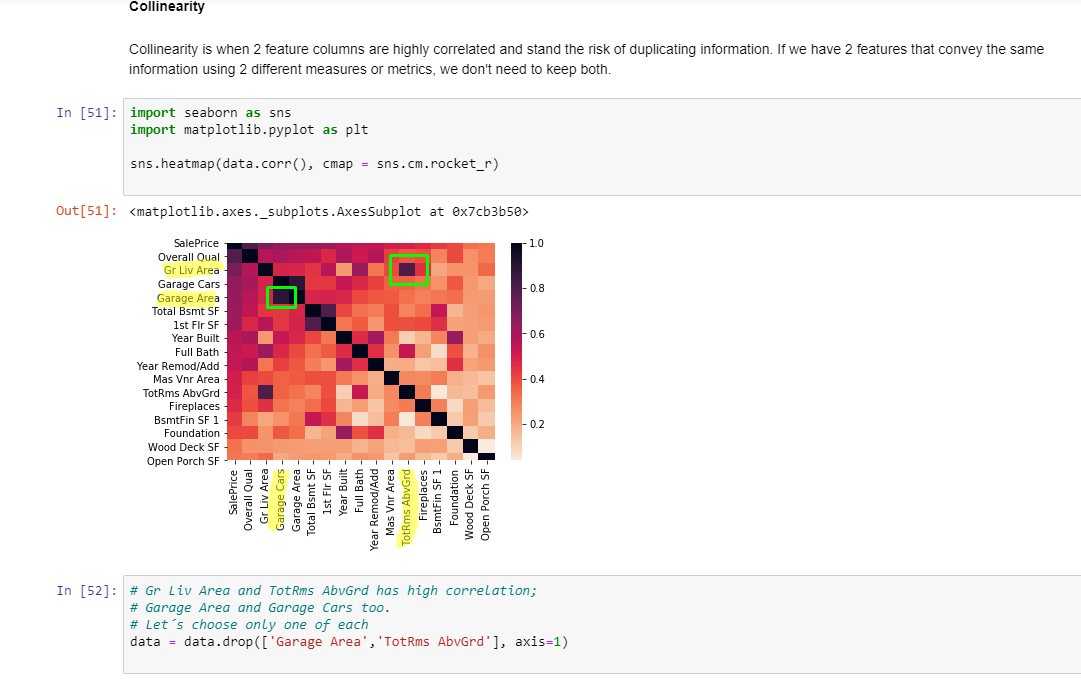
Colinearidade
A colinearidade ocorre quando duas colunas de features são altamente correlacionadas e correm o risco de duplicar informações. Se tivermos dois recursos que transmitem as mesmas informações usando duas medidas ou métricas diferentes, não precisamos manter os dois.
Perceba que Gr Liv Area e TotRms AbvGrd tem uma alta correlação, assim como Garage Area e Garage Cars. Logo, apenas uma de cada será necessária permanecer no dataset
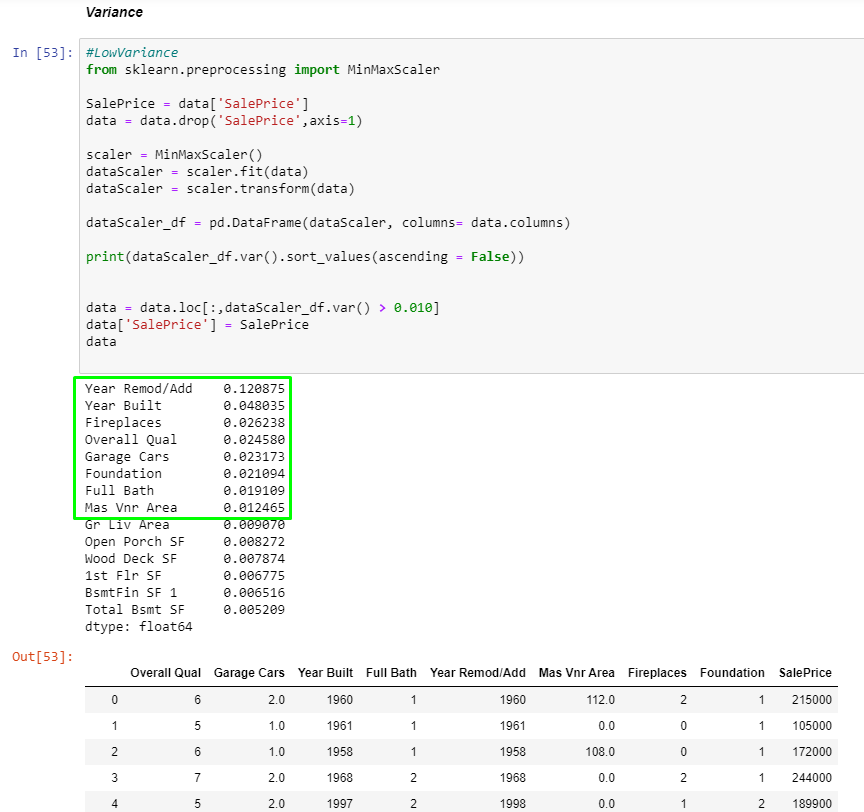
Variação
Quando temos uma feature com baixa variação, ela não contribui muito para nosso modelo, já que varia pouco a informação. Por exemplo, uma feature onde todas as linhas possuem uma mesma informação, sua variação será zero. Para nosso modelo, estipulamos uma variação maior que 0.010
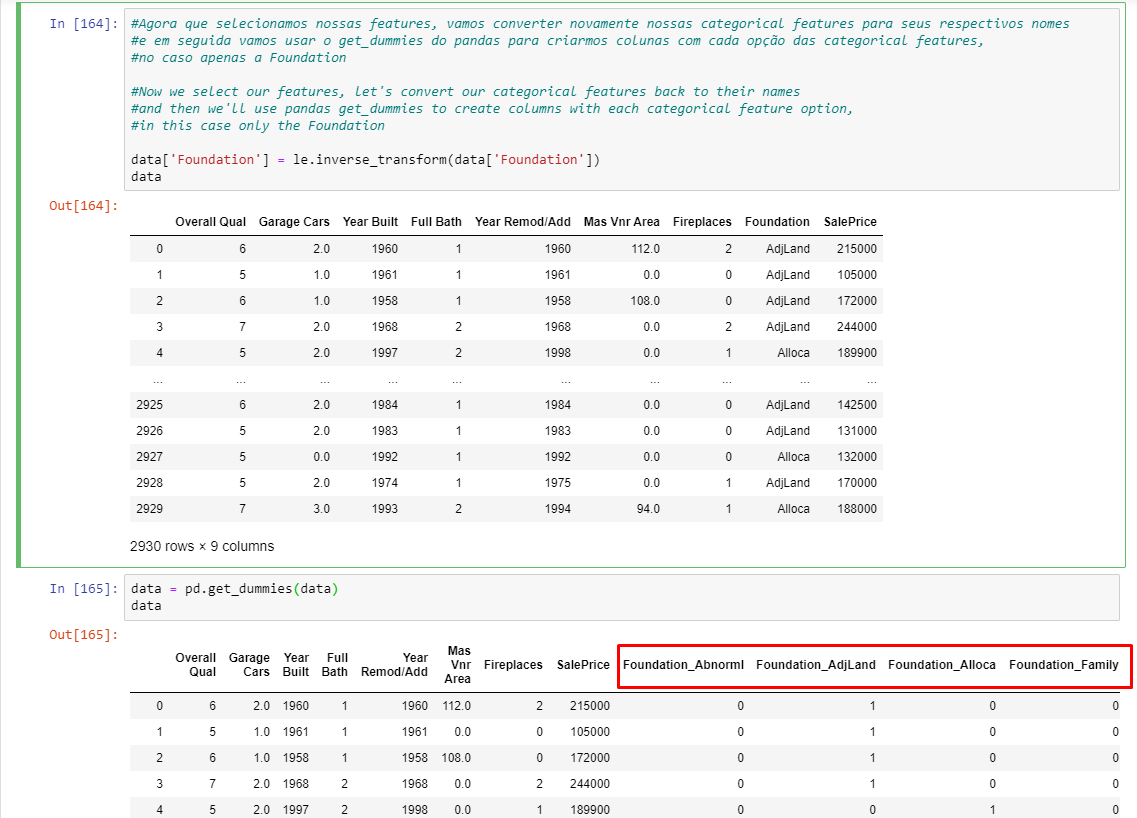
Pegamos então nossas categorical features que havíamos anteriormente convertido para número e invertemos novamente para labels.
Finalizamos pegando todas as categorical features (no caso restou apenas a “foundation”) e aplicamos o get_dummies do pandas para que seja criada uma coluna para cada categoria.
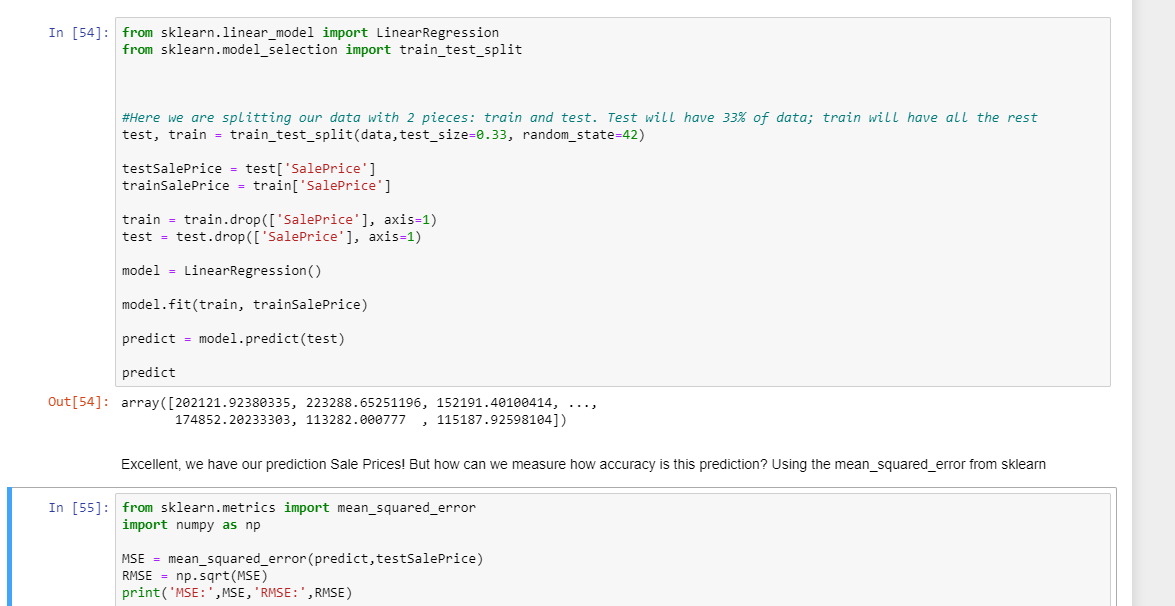
Por fim colocamos nossos dados em nosso modelo
Você pode baixar o código do arquivo clicando aqui e o dataset clicando aqui


