
O Apache HBase é um banco de dados não relacional (NoSQL) de código aberto, distribuído, baseado no paper do Google Bigtable: A Distributed Storage System for Structured Data / sistema de armazenamento distribuído para dados estruturados Google
O objetivo do projeto é conseguir realizar o armazenamento de tabelas realmente grandes (bilhões de linhas x milhões de colunas) utilizando clusters comuns.
Com isto dito, vamos realizar um projeto aonde buscaremos informações de um banco de dados MySQL com Sqoop, salvando os dados em uma base Hbase.
Utilizaremos a VM Cloudera. A VM Cloudera conta com todas as ferramentas necessárias para nosso exemplo.
Vamos utilizar também a base de dados MySQL que utilizamos em nosso post: Hadoop: copiando dados de um banco relacional MySQL para o HDFS utilizando Sqoop e consultando dados utilizando Hive
Vamos abrir o terminal de nossa VM e digitar:
1 | hbase shell |
Vamos criar agora nossa tabela employees:
1 | create 'employeesHBASE' , 'emp_no', 'birth_date', 'first_name', 'last_name', 'gender', 'hire_date' |
Isto criará nossa tabela employeesHBASE. Digite exit para voltarmos ao inicio do terminal.
Precisamos integrar o serviço do Hbase e do Hive para que seja possível o Hive acessar os dados vindos do Hbase, como mostra a documentação da Cloudera:
https://www.cloudera.com/documentation/enterprise/5-13-x/topics/cdh_ig_hive_hbase.html

Vamos agora importar os dados da nossa tabela employees de nosso banco relacional MySQL para nosso banco NoSQL Hbase
1 | sqoop import --connect jdbc:mysql://localhost:3306/employees --username root --password cloudera --table employees --hbase-table employeesHBASE --column-family last_name --hbase-row-key emp_no -m 1 |
Vamos visualizar agora estes dados em nosso HUE. Em seu navegador firefox, clique no atalho do HUE, clique no botão hbase e e em seguida em nossa tabela criada:

Excelente. Para facilitar nossas consultas, o ideal seria se fosse possível utilizarmos SQL para isso. Como não estamos trabalhando com um banco relacional, o Hive irá nos ajudar nesta tarefa, utilizando seu HQL. Para isso, vamos criar uma EXTERNAL TABLE, que ficará “em cima” de nossa table Hbase, tornando-se possível estas consultas.
INTERNAL TABLE – Hive Managed Tables
Quando criamos uma tabela no Hive, ela, por padrão, gerencia os dados. Isso significa que o Hive move os dados para o diretório do warehouse.
EXTERNAL TABLE
Nós também podemos criar uma tabela externa. Ele diz ao Hive para se referir aos dados que estão em um local existente fora do diretório do warehouse.
Fonte: https://data-flair.training/blogs/hive-internal-tables-vs-external-tables/
Vamos então criar nossa external table:
1 2 3 4 5 | hive shell CREATE EXTERNAL TABLE employeesHIVE (key INT,emp_no INT, birth_date DATE, first_name STRING, last_name STRING, gender STRING, hire_date DATE ) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key, last_name:emp_no, last_name:birth_date, last_name:first_name, last_name:last_name, last_name:gender, last_name:hire_date") TBLPROPERTIES("hbase.table.name" = "employeesHBASE"); |
Conseguimos agora dar um SELECT em nossa tabela Hbase:
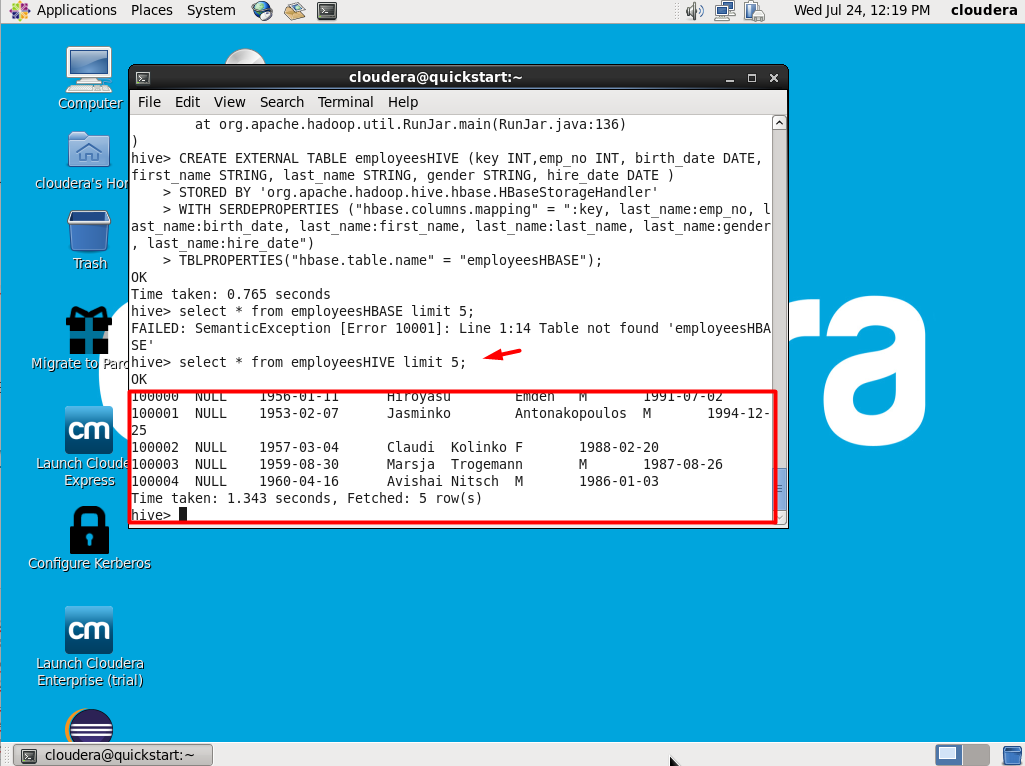
Se preferir, use o HUE também:

