Com o pandas é possível trabalhar de forma muito facilitada com as mais diversas formas de dados e formatos. Uma delas é carregar dados de um json para um dataframe:
1 2 3 | import pandas as pd df = pd.read_json(path_or_buf='URL ou caminho do arquivo / URL or filepath') |
Porém quando estamos trabalhando com json aninhados / nested json, não fica mais tão simples (mas ainda sim, simples)
Nested json são “jsons dentro de um json”, e para conseguir alcançar esta informação, alguns parâmetros devem sem cumpridos.
Como exemplo, usaremos um json aonde estão listados todos os episódios da série Game Of Thrones, hospedado em:
http://api.tvmaze.com/singlesearch/shows?q=game-of-thrones&embed=episodes
Se tentarmos usar o mesmo código do início do post, receberemos este erro:
ValueError: Mixing dicts with non-Series may lead to ambiguous ordering.
Para contornarmos esta situação, usaremos o código abaixo:
1 2 3 4 5 6 7 8 9 10 | !pip install requests !pip install pandas #Usaremos a biblioteca 'requests' para buscar os dados na url informada #We will use de library 'requests' to catch the data in the url dataRequest = requests.get(url='http://api.tvmaze.com/singlesearch/shows?q=game-of-thrones&embed=episodes') #Convertemos em formato json os dados novamente #We convert to json format again data_json = dataRequest.json() |
Mas se você visualizar este arquivo json em algum “beautifier code sites” como o https://codebeautify.org/jsonviewer você conseguirá enxergar melhor aonde está a informação que precisamos (no caso, a temporada, o episódio e o nome do episódio):
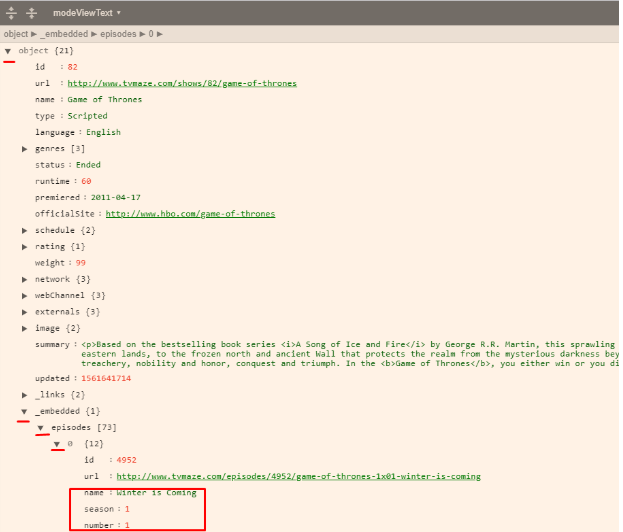
É aqui que entra a função json_normalize da biblioteca pandas, aonde alguns parâmetros devem ser informados:
data: valores não serializados
record_path: Caminho do objeto aonde estão os valores
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from pandas.io.json import json_normalize data_normalize = json_normalize( #Dados deserializados #Unserialized JSON objects data=data_json['_embedded'] #Caminho do objeto aonde estão os dados #path of the data that you need ,record_path='episodes' #Prefixo das colunas. Recomendado usar para evitar ambiguidade de colunas # Columns prefix. Recommended to use to avoid ambiguous name columns ,record_prefix='got_' ) #Listaremos apenas as colunas que precisamos #Listing only the columns that we will need data = data_normalize[['got_season','got_number','got_name']] |
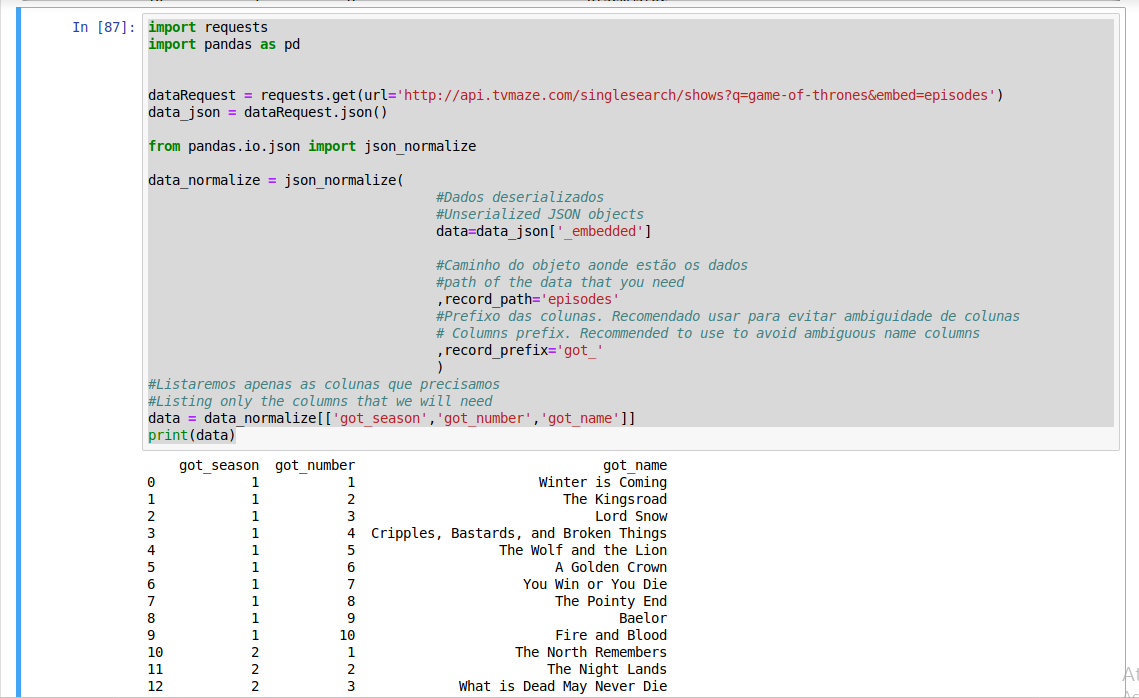
Código no github:
https://github.com/marcelpinheiro/malum/blob/master/drops-nested-json-e-pandas.py