Neste post usaremos o Ubuntu como sistema operacional para rodar nossas aplicações.
Em um post anterior, vimos como criar um cluster Kafka utilizando os serviços da AWS. Desta vez faremos tudo em um ambiente local Linux.
Vamos la!
Instalando o Kafka
- Realize o download do Kafka – https://kafka.apache.org/downloads
- Procure pelos Binary downloads e copie o endereço do link.
- descompacte o arquivo
- Instale o Java na máquina
O comando abaixo fará tudo isso:
1 2 3 | apt-get install default-jdk wget https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz tar -xzf kafka_2.12-2.1.0.tgz |
Agora temos tudo do que precisamos para rodar o Kafka
Obs: O Kafka precisa do Zookeeper para rodar, porém ele já vem no pacote original do Kafka, com algumas limitações. Mas para para objeto de estudo, sem problemas.
Antes de iniciar seu servidor Kafka, edite o arquivo server.properties, dentro da pasta config:
cd config/
vi server.properties
Com as setas do teclado, vá até a linha com a palavra listeners, aperte a tecla i e descomente a linha
Aperte ESC
Digite dois pontos “:”, digite “x” e de ENTER
Iniciando o Zookeeper
Entre na pasta descompactada do kafka e digite o comando abaixo:
1 | bin/zookeeper-server-start.sh config/zookeeper.properties |
Iniciando o servidor Kafka
Dentro da pasta do Kafka, digite o comando
1 | bin/kafka-server-start.sh config/server.properties |
Estamos prontos agora para criar nosso tópico com o Producer e consumirmos os dados com nosso Consumer
Criando um tópico
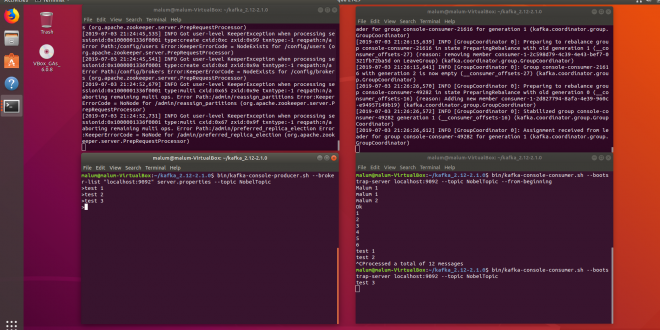
1 | bin/kafka-console-producer.sh --broker-list "localhost:9092" server.properties --topic NobelTopic |
Após a criação do tópico, digite algumas linhas e aperte ENTER. Elas serão as mensagens que serão consumidas ao ler o tópico
Consumindo o tópico
1 | bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic NobelTopic --from-beginning |
