Em machine learning, uma das partes mais importantes é a feature engineering. Este post tratará da conversão de categorias com classes string para numérico (colunas texto para números inteiros), já que os algoritmos de ML trabalham com números.
Para cada classe da feature (ou a cada categoria de uma coluna), será criado uma nova coluna.
Mas você deve estar se perguntando: por que simplesmente não atribui um número a cada categoria? Exemplo:
Coluna car type com as opções : sedan, suv, hatch
Poderíamos simplesmente converter em: 1 – sedan, 2 – suv, 3 – hatch
Esta não é uma boa abordagem porque como algoritmos realizam equações matemáticas, não faria sentido por exemplo 1 (sedan) + 2 (suv) = 3 (hatch)
Veja mais em https://malum.com.br/wp/2019/11/24/normalizando-dados-com-sklearn/
Primeiro vamos carregar nossos dados em nosso pandas dataframe.

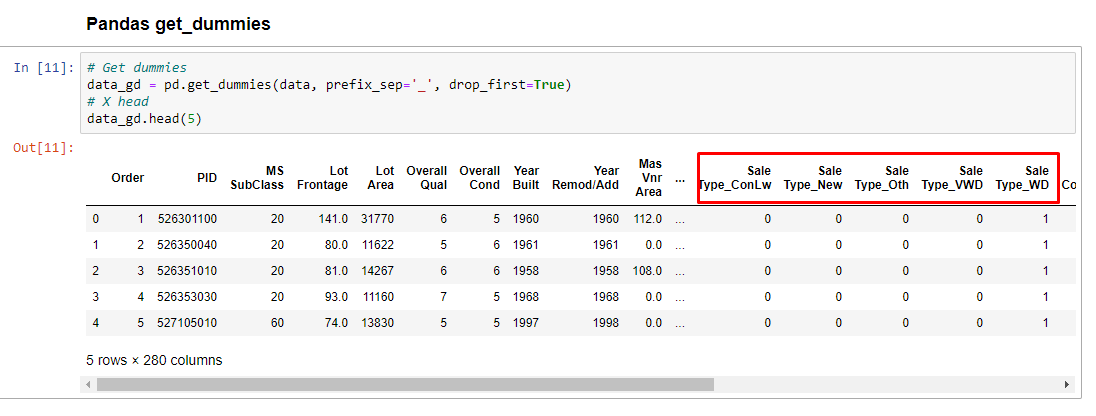
Pandas get_dummies
A vantagem desta funcionalidade é que é possível usá-la diretamente no dataframe, identificando as features e categorizando. Cria-se colunas novas para cada classe da categoria. A opção drop_first está como true para evitar problemas de multicolinearidade.
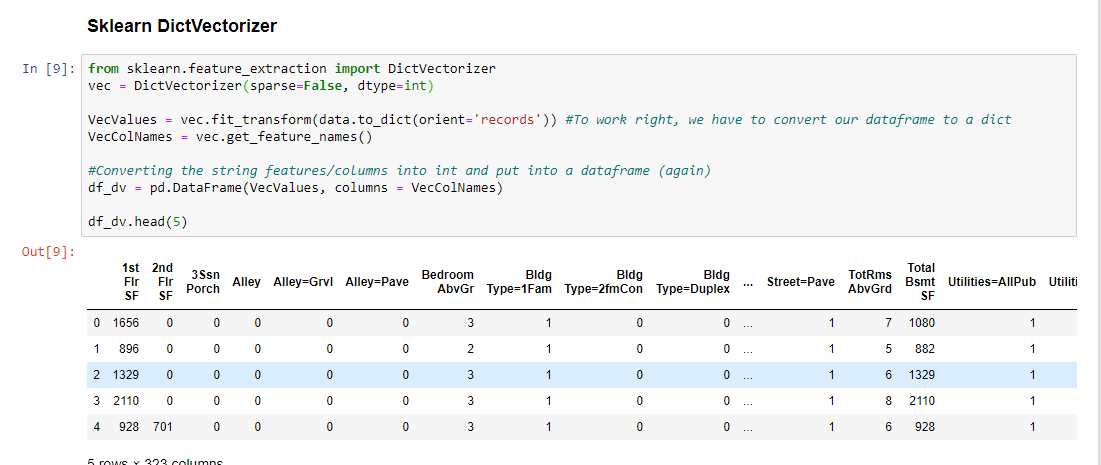
Sklearn DictVectorizer
Esta abordagem é recomendada quando há centenas ou milhares de categorias e features. Apesar de ser mais complexa, ela suporta sparse matrix outputs. Como ela trabalha apenas com dicts, deve-se converter o dataframe para poder utilizá-la. O resultado é um numpy array.
No exemplo abaixo nós convertemos em dict, realizamos a conversão de dados e em seguida colocamos novamente em um dataframe:
Faça o download do código clicando aqui