Quando trabalhamos com algoritmos de machine learning, existe sempre a recomendação de que todos os dados a serem trabalhados sejam numéricos. Porém no mundo real isto raramente acontece, pois nossos dados muitas vezes possuem categorias descritivas (string).

Neste exemplo vemos que o atributo neighborhood é um texto, logo precisamos converte-lo em número. Você deve ter pensado na seguinte solução: Por que simplesmente não converto em números diretamente esta categoria, como por exemplo:
ID 1 – ‘Copacabana’
ID 2 – ‘Ipanema’,
ID 3 – ‘Brooklyn’,
ID 4 -‘Queens’
O problema desta solução é que o Sklearn considera números como quantidades algébricas, então ele tentaria por exemplo somar estes IDs, oque não faria nenhum sentido.
Por exemplo: Copacabana(1) + Ipanema(2) = Brooklyn(3) ?
Para resolver este problema, a biblioteca Sklearn possui uma feature engineering muito interessante chamada DictVectorizer.
Ela cria novas colunas referentes á quantidade de itens de uma categoria. No caso de neighborhood nós possuímos 4: Copacabana, Ipanema, Brooklyn e Queens, então 4 colunas novas são criadas. Aonde cada uma é correspondente, o número 1 é preenchido, as outras permanecem com 0:
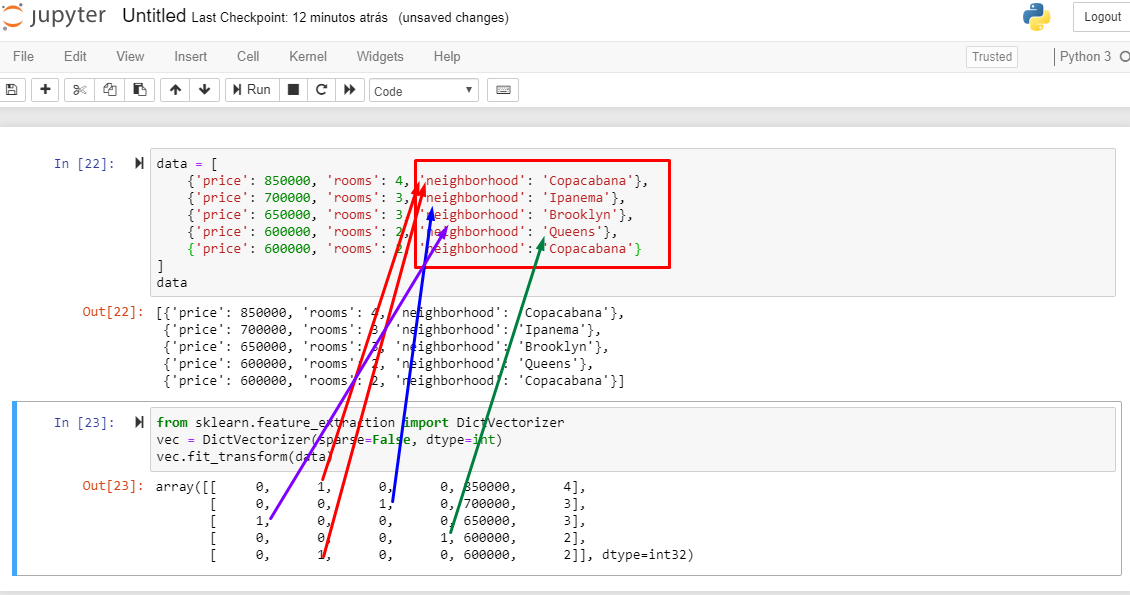
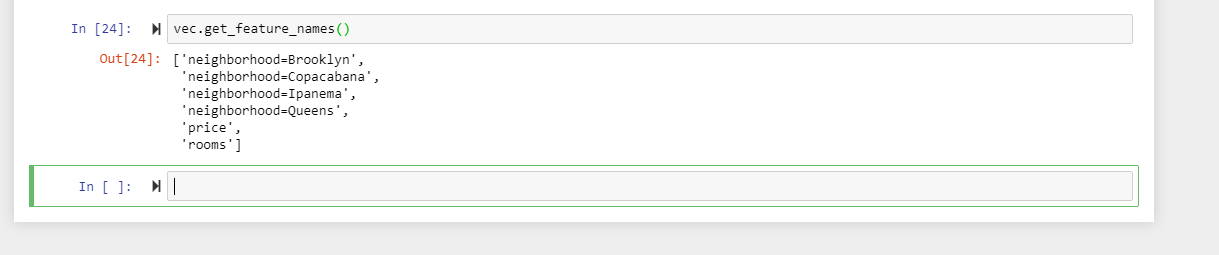
Utilizando o código abaixo, conseguimos verificar as categorias criadas:
Esta solução também possui um problema: dependendo da quantidade de colunas e categorias, você terá dezenas ou centenas de colunas.

Uma solução é setar o Sparse = True. Desta maneira ele armazena todos as células com 0 em um Compressed Sparse Row format:

Faça o download do código clicando aqui
Referência: Python Data Science Handbook