![]()
O Avro é um sistema de serialização de dados de software livre que ajuda na troca de dados entre sistemas, linguagens de programação e estruturas de processamento. O Avro ajuda a definir um formato binário para seus dados, bem como mapeá-lo para a linguagem de programação de sua escolha.
Um dos principais benefícios de se utilizar o Avro é a validação dos dados antes de serem inseridos no destino e a “auto documentação” utilizando schemas. O schema possui informações de quais dados e que tipo de dados se espera, além de um espaço para documentar oque aquilo significa, utilizando a tag “doc”.
Neste post, utilizaremos tudo o que foi aprendido no post Drops: nested json e pandas para aplicarmos no Avro.
O código abaixo executará o seguinte:
- Instala os pacotes necessários para a aplicação (estou usando Jupyter Notebook)
- – Busca as informações de um arquivo json de uma URL com a lista de todos as temporadas, episódios e título do episódios da série Game Of Thrones
- Cria uma string com o Schema (geralmente o schema é feito em um arquivo separado com extensão *.avsc, mas para ficar mais fácil a visualização eu passei em uma string
- Import dos pacotes são feitos; a variável schema é passada para o Avro; é criado o arquivo got_malum.avro passando como parametro a variável schemaParse aonde ela valida se os dados estão de acordo com o schema; percorremos a variável data e escrevemos em got_malum.avro
Com isto teremos um arquivo serializado, desta maneira:
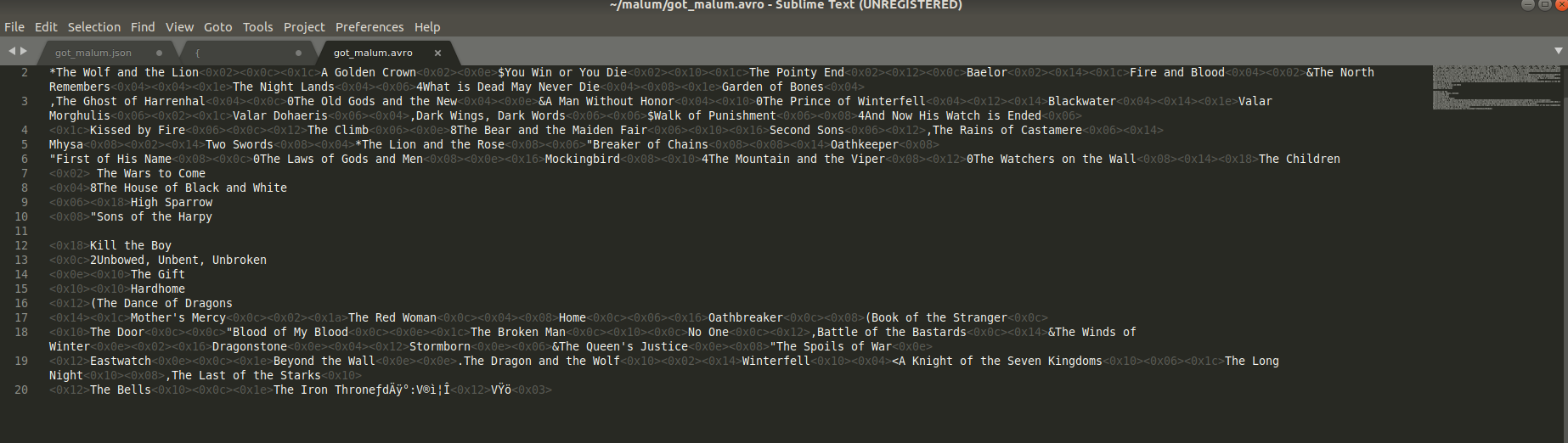
O Avro serializa os dados de forma compacta reduzindo tamanho dos dados
5 – Nós lemos o arquivo

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | #!/usr/bin/env python # coding: utf-8 # In[125]: #1 !pip install avro-python3 !pip install requests !pip install pandas #2 import requests import pandas as pd dataRequest = requests.get(url='http://api.tvmaze.com/singlesearch/shows?q=game-of-thrones&embed=episodes') data_json = dataRequest.json() from pandas.io.json import json_normalize data_normalize = json_normalize( #Dados deserializados #Unserialized JSON objects data=data_json['_embedded'] #Caminho do objeto aonde estão os dados #path of the data that you need ,record_path='episodes' #Prefixo das colunas. Recomendado usar para evitar ambiguidade de colunas # Columns prefix. Recommended to use to avoid ambiguous name columns ,record_prefix='got_' ) #Listaremos apenas as colunas que precisamos #Listing only the columns that we will need data = data_normalize[['got_season','got_number','got_name']] #3 #Usamos 3 aspas duplas para tudo virar string / We use triple doouble quotes to everything inside be string schema = """{ "type": "record", "name": "GOTLIST", "fields" : [ {"name": "got_season", "type": "int", "doc": "Número da temporada / Season number"}, {"name": "got_number", "type": "int", "doc": "Número do episódio / Episode number"}, {"name": "got_name", "type": "string", "doc": "Título do episódio / Episode title"} ] }""" #4 import avro.schema from avro.datafile import DataFileReader, DataFileWriter from avro.io import DatumReader, DatumWriter import pandas as pd schemaParse = avro.schema.Parse(schema) #Aqui nós criaremos um arquivo com a lista de episódios com o schema para validação #Here we create a file of GOT episodes list with the schema for validation writer = DataFileWriter(open("got_malum.avro", "wb"), DatumWriter(), schemaParse) # writer.append({"got_season": 1, "got_number": 1, "got_name": "Test"}) #Agora iremos inserir os dados da variavél data no arquivo got_malum.avro #Now we will insert the data from the data variable in the got_malum.avro file for index, rows in data.iterrows(): writer.append({"got_season": rows['got_season'], "got_number": rows['got_number'], "got_name": rows['got_name']}) writer.close() #5 #Lendo o arquivo (deserializar) / reading the file (Deserialization) reader = DataFileReader(open("got_malum.avro", "rb"), DatumReader()) for user in reader: print(user) reader.close() |
Faça o downloads dos arquivos:
https://github.com/marcelpinheiro/malum/blob/master/avro.py
https://github.com/marcelpinheiro/malum/blob/master/avro.ipynb