Marcel Pinheiro 13/07/2019 BIG DATA 1,925
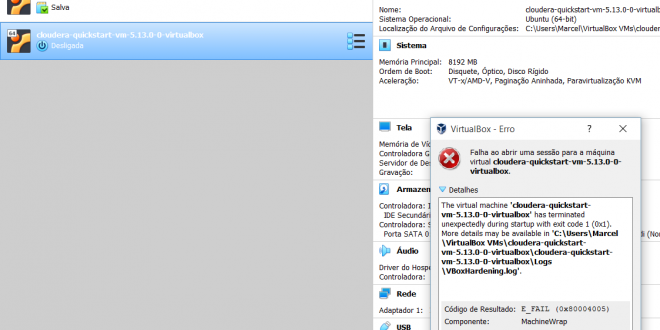
Algumas vezes quando temos VMs com o VirtualBox com o IBM Rapport (aplicativo de proteção geralmente instalado com os sistemas de proteção de internet banking), ocorre um erro. Para contorná-lo: Reinicie o seu PC para entrar no modo de segurança automaticamente. Faça logon no seu computador com uma conta de …
Read More » Marcel Pinheiro 11/07/2019 BIG DATA, Linux 2,090
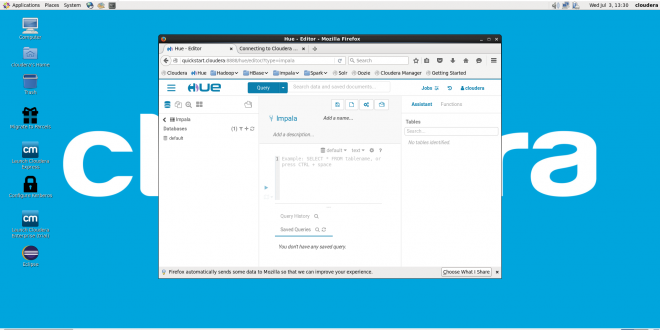
Neste post utilizaremos um banco de dados Mysql aonde copiaremos dados de tabelas e salvaremos no HDFS do Hadoop. Em seguida listaremos estas informações utilizando o Hive. Utilizarei a VM da Cloudera aonde contém tudo oque precisaremos para este exemplo. A base de dados será a Employees Sample Database, encontrada …
Read More » Marcel Pinheiro 09/07/2019 BIG DATA 2,146
O Avro é um sistema de serialização de dados de software livre que ajuda na troca de dados entre sistemas, linguagens de programação e estruturas de processamento. O Avro ajuda a definir um formato binário para seus dados, bem como mapeá-lo para a linguagem de programação de sua escolha. Um …
Read More » Marcel Pinheiro 07/07/2019 BIG DATA 3,705
Com o pandas é possível trabalhar de forma muito facilitada com as mais diversas formas de dados e formatos. Uma delas é carregar dados de um json para um dataframe: [crayon-6625f1708e286208184805/] Porém quando estamos trabalhando com json aninhados / nested json, não fica mais tão simples (mas ainda sim, simples) …
Read More » Marcel Pinheiro 03/07/2019 BIG DATA, Linux 959
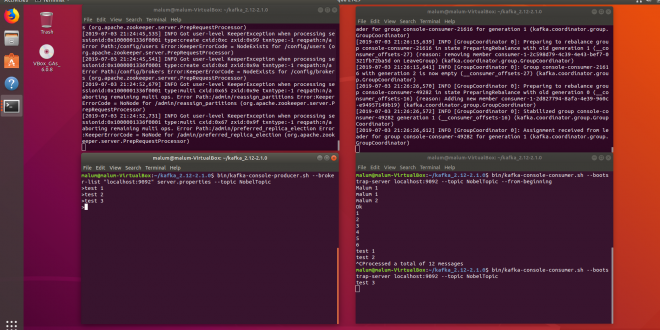
Neste post usaremos o Ubuntu como sistema operacional para rodar nossas aplicações. Em um post anterior, vimos como criar um cluster Kafka utilizando os serviços da AWS. Desta vez faremos tudo em um ambiente local Linux. Vamos la! Instalando o Kafka Realize o download do Kafka – https://kafka.apache.org/downloads Procure pelos …
Read More » Marcel Pinheiro 03/07/2019 BIG DATA 1,316
A Cloudera, Inc. é uma empresa de software com sede nos EUA que fornece uma plataforma de software para engenharia de dados, data warehousing, aprendizado de máquina e análise que é executada na nuvem ou nas instalações. A Cloudera foi fundada em 2008 por três engenheiros do Google, Yahoo! e …
Read More » Marcel Pinheiro 02/07/2019 AWS, BIG DATA 4,296
Dando continuidade ao nosso projeto, vamos agora começar a trabalhar com o Apache Kafka utilizando o serviço MSK da Amazon 2 – Criando um cluster Kafka De volta ao AWS, no canto superior esquerdo, clique em services novamente e procure por MSK Dentro do MSK, clique em create cluster. De …
Read More » Marcel Pinheiro 01/07/2019 AWS, BIG DATA 2,101
Neste post, nós consumiremos dados streaming utilizando Kafka através do serviço da AWS chamado MSK – Managed Streaming for Kafka Para isto utilizaremos: https://aws.amazon.com Amazon Web Services , também conhecido como AWS, é uma plataforma de serviços de computação em nuvem, que formam uma plataforma de computação na nuvem …
Read More » Marcel Pinheiro 01/07/2019 BIG DATA 1,629
Anaconda (https://www.anaconda.com/distribution/) é uma plataforma em python (e também em R) para Data Science. Possui diversas aplicações para o desenvolvimento de soluções em biga data, aonde tudo fica reunido em seu Anaconda Navigator. Dentre as aplicações podemos citar: Jupyter Notebook Aplicativo da Web de código aberto que permite criar e …
Read More » Marcel Pinheiro 30/06/2019 Uncategorized 1,868
Feedparser (https://pypi.org/project/feedparser/) é um pacote para python aonde é possível ler RSS (Rich Site Summary) feeds. O pacote trabalha com RSS 0.9x, RSS 1.0, RSS 2.0, CDF, Atom 0.3, e Atom 1.0 feeds O código abaixo realiza a instalação do pacote e busca os últimos feeds do blog Cloudflare, utilizando …
Read More »