Neste post utilizaremos um banco de dados Mysql aonde copiaremos dados de tabelas e salvaremos no HDFS do Hadoop. Em seguida listaremos estas informações utilizando o Hive.
Utilizarei a VM da Cloudera aonde contém tudo oque precisaremos para este exemplo.
A base de dados será a Employees Sample Database, encontrada na documentção oficial do MySQL:
https://dev.mysql.com/doc/employee/en/
Caso precise de ajuda na instalação da VM, acesso nosso post:
Com a VM já ligada, acesse o terminal e faça o download da base dados:
wget https://github.com/datacharmer/test_db/archive/master.zip
Para descompactar o arquivo:
unzip master.zip
Acesse agora a pasta test_db_-master:
cd test_db-master/
Vamos agora carregar nossa base de dados baixada em nosso MySQL:
mysql -uroot -pcloudera < employees.sql
Para verificar se tudo deu certo, digite o comando:
mysql -uroot -pcloudera
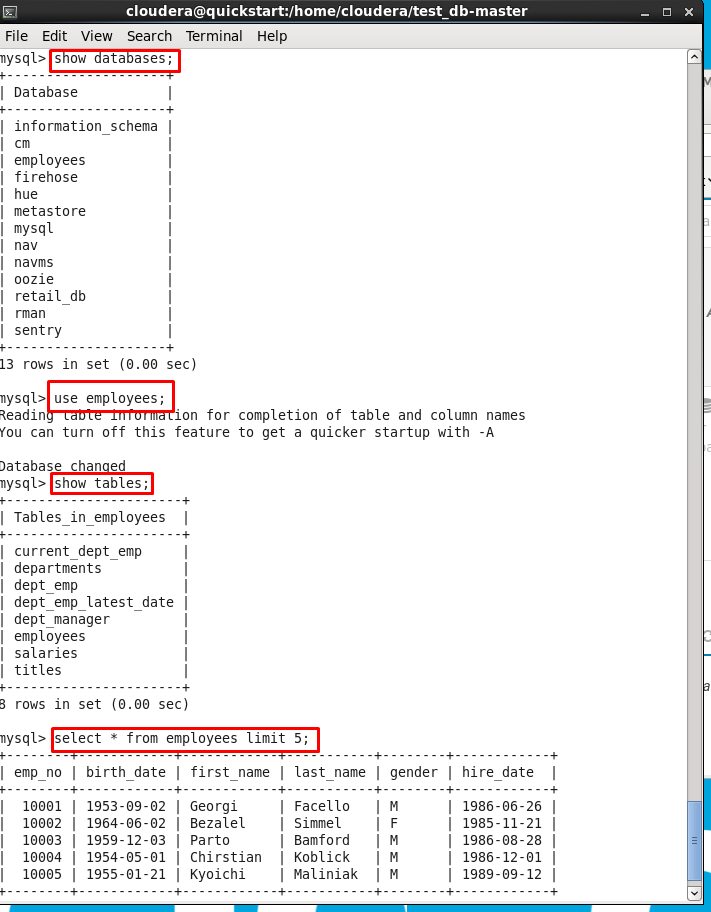
Em seguida vamos listar todas as databases de nosso servidor MySQL:
show databases;
Se tudo deu certo, veremos a database employees listada. Vamos selecioná-la:
use employees;
Vamos listar todas as tabelas desta base de dados:
show tables;
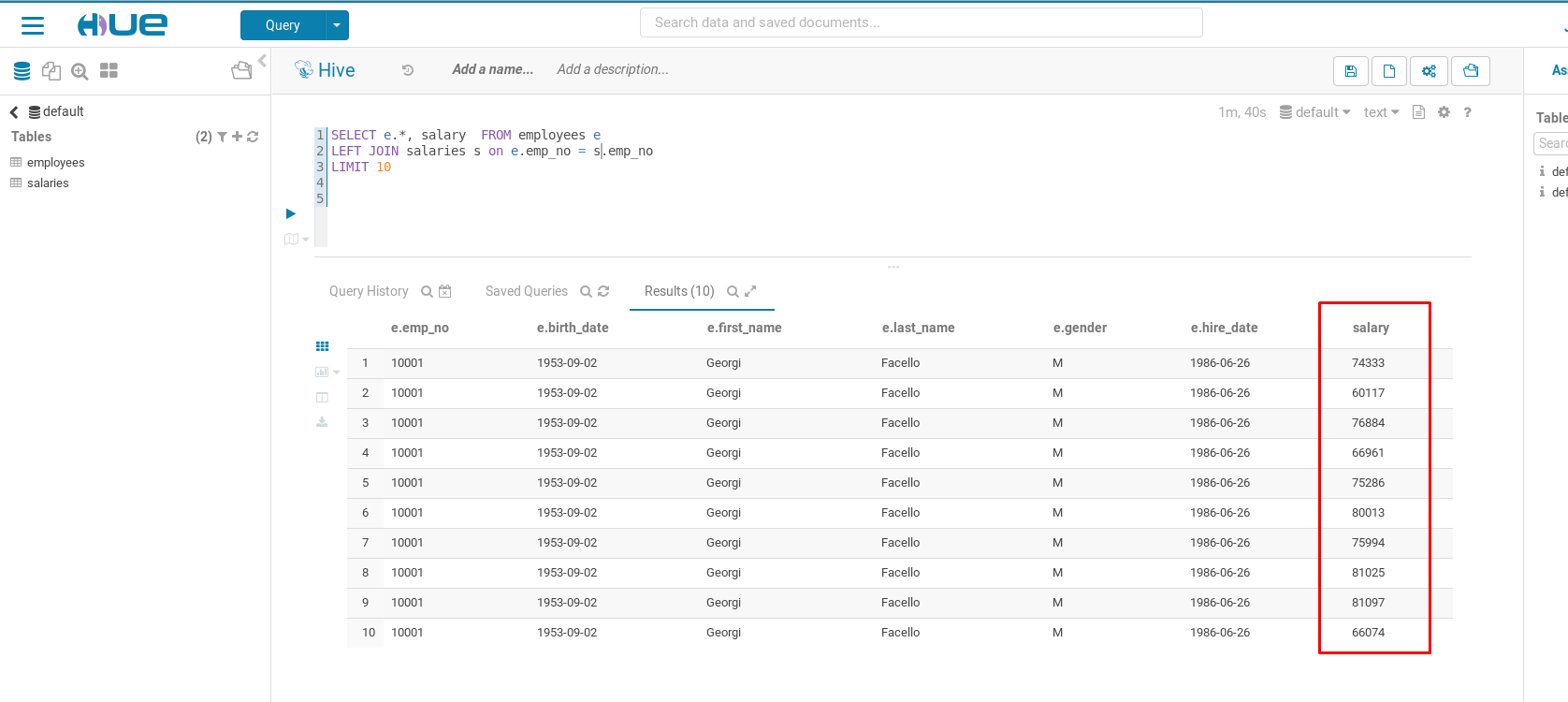
Vamos verificar os primeiros 5 registros da tabela employees:
select * from employees limit 5;
Tudo certo! Vamos agora carregar algumas tabelas da base de dados em nosso HDFS e aproveitar e já criar nossas tabelas no Hive.
sqoop import –connect jdbc:mysql://localhost:3306/employees –username root –password cloudera –table employees –hive-import
Vamos importar também a tabela salaries:
sqoop import –connect jdbc:mysql://localhost:3306/employees –username root –password cloudera –table salaries –hive-import
Perceba que o comando inicia o map reduce no HDFS:
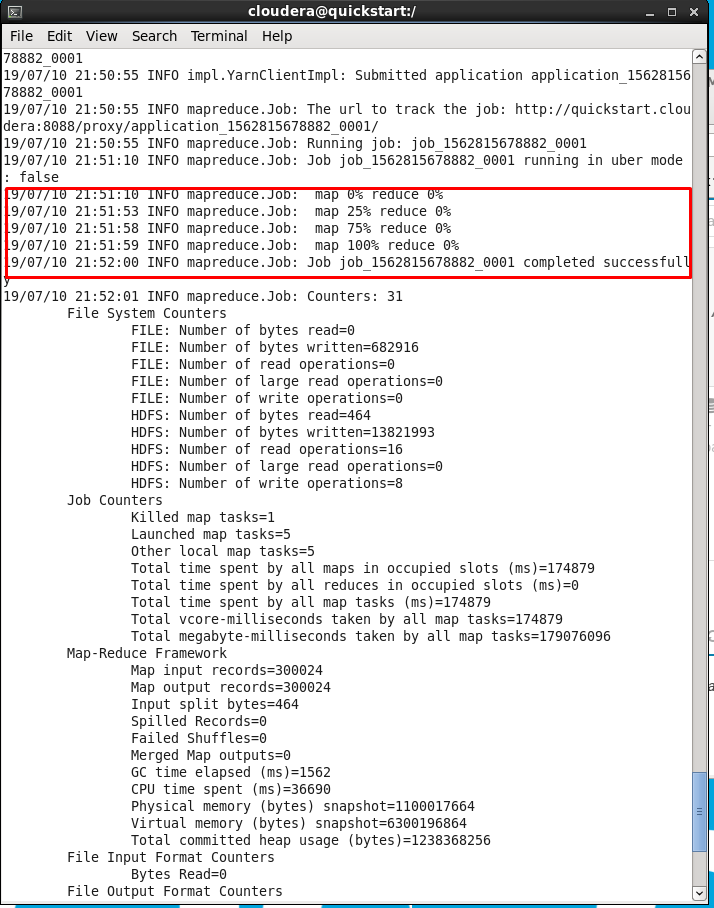
Uma observação é que o Hive armazena seus dados também no HDFS do Hadoop
Hora de vermos tudo funcionando no Hive!
Vamos acessar nosso HUE:
http://quickstart.cloudera:8888/
Em Query, vamos acessar nosso editor Hive
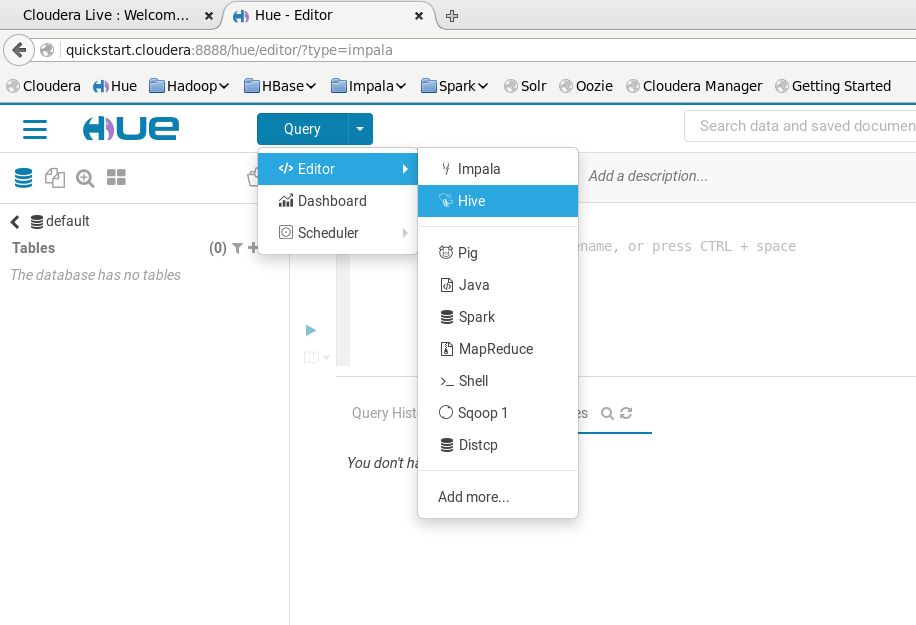
Como não foi passado nenhum parâmetro de qual database utilizar, o Hive cria em seu database default por padrão.
A partir de agorá é possível fazer suas consultas utilizando o HQL, muito similar ao SQL:
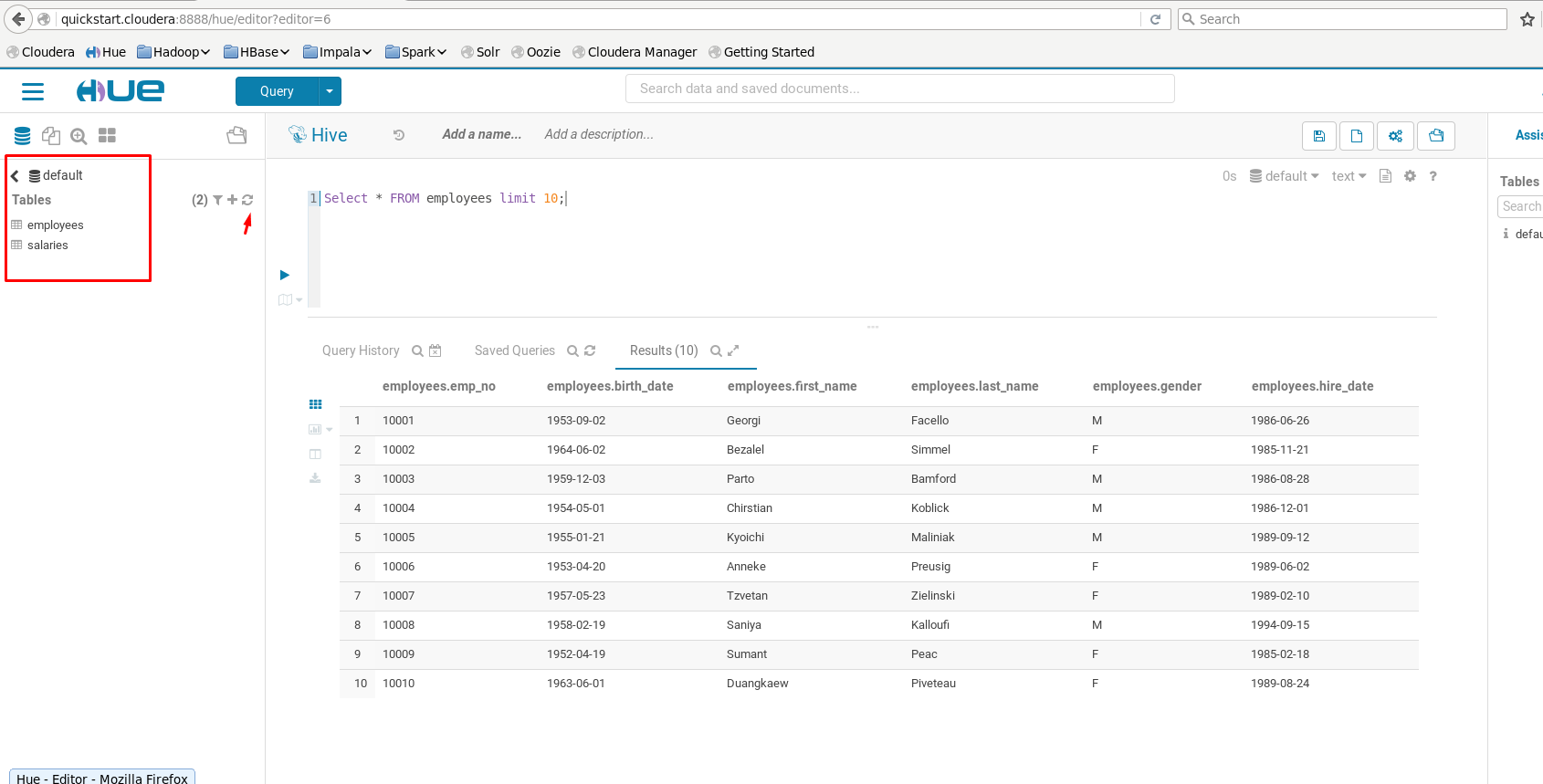
Com o HQL é possível realizar diversos tipos de consultas, como joins, count, e etc